Operating in spite of uncertainty
A framework for nature data evaluation

The map is not the territory.
This expression from Alfred Korzybski – that a map is a model of reality, not reality itself – could not be more apt for nature data. Every dataset we create is a model of nature. But nature is a mosaic of interconnected ecosystems, each containing many thousands of interacting components that vary over time and space. This staggering complexity makes it impossible to model nature perfectly. Every measurement, no matter how sophisticated, is still an estimate.
As nature data users, we must operate in spite of this uncertainty. We must decide which datasets to apply to different contexts, the level of accuracy needed for a use case, and how much to work and pay for higher performance. These decisions matter, with poor dataset choices contributing to overclaimed carbon credits, delayed wildfire warnings, and misdirected conservation efforts.
We believe that this decision process – i.e., dataset evaluation – must be standard practice in nature data workflows, yet many teams lack the tools to do it. This newsletter introduces how we are thinking about dataset evaluation at Cecil. We first explore different sources of uncertainty and how they manifest in nature data. We then propose a three-pillar framework for evaluating nature datasets, which we’re operationalising on the Cecil platform.
Sources of uncertainty in nature data
Generating nature data is a multistep journey, from deciding what to measure, to designing protocols, to collecting and processing data. External factors and decisions along this journey create different sources of uncertainty:
Conceptual mismatches – not measuring a variable directly (e.g., using spectral diversity as a proxy for species diversity).
Instrument limitations – biases or limits in equipment (e.g., soil temperature probes only measuring to 10 cm depth where plant roots extend to 30 cm).
Environmental conditions – local conditions affecting measurements (e.g., cloud cover partially obscuring satellite sensor readings).
Methodology – design decisions and tradeoffs (e.g., optimising models for time series change detection at the expense of individual observation accuracy).
Data processing – artefacts introduced by data wrangling (e.g., sharp lines appearing on rasters due to mosaicking of input data tiles).
Human error – mistakes in measuring or recording data (e.g., species misidentification in field surveys).
These uncertainties primarily affect dataset performance in two ways:
Accuracy – the proximity of a measurement to the true value (e.g., a rainfall sensor reads 80 mm when rainfall is actually 100 mm).
Precision – the similarity/consistency of repeat measurements (e.g., repeat readings of 95 mm, 105 mm, 114 mm).
Data providers often express these uncertainties through confidence intervals, which represent the range within which the true value falls (e.g., 100 ± 20 mm).
Sources of uncertainty can occur individually or together, with multiple sources often having compounding effects on performance. For example, even modest errors in vegetation height and wood density measurements can propagate into larger errors when combined in a biomass calculation.
Uncertainty also varies at different scales of data aggregation. For instance, in remote sensing datasets pixel-level uncertainty is often high, but uncertainty decreases as pixel values (and their uncertainties) are aggregated to make estimates over larger areas.
A framework for nature data evaluation
It is impossible to solve for all uncertainty in nature data – and it’s not necessary to. Yet to make informed decisions, users need a systematic way to evaluate how uncertainty impacts dataset performance. Industries like pharmaceutical research and weather forecasting have made dataset evaluation standard practice. But the nature data sector has yet to do so. Our users regularly ask "which dataset performs best?" And without a shared framework and resources, there’s no obvious answer.
At Cecil, we're building tools to change this, which revolve around a three-pillar framework of dataset evaluation: (1) dataset inspection for initial screening, (2) cross-comparisons among multiple options, and (3) benchmarking accuracy against a source of truth.
Dataset inspection
Dataset inspection is the process of checking the details and behaviour of a single dataset to confirm it is suitable for a use case:
Dataset applicability – checking documentation to confirm a dataset measures what you need it to (e.g., has spatial coverage for your area of interest) and the methodology is appropriate (e.g., has sensitivity to detect expected values or change). Reveals conceptual mismatches, instrument limitations, and methodology issues.
Expected behaviour – exploring patterns in dataset values and confidence intervals that may signal a problem (e.g., step changes in values due to updates in sensor technology). Reveals effects of environmental conditions, data processing issues, and human error.
Use case sensitivity – confirming that a dataset is able to detect a relevant event (e.g., deforestation in your region of interest). Reveals how all sources of uncertainty impact suitability.
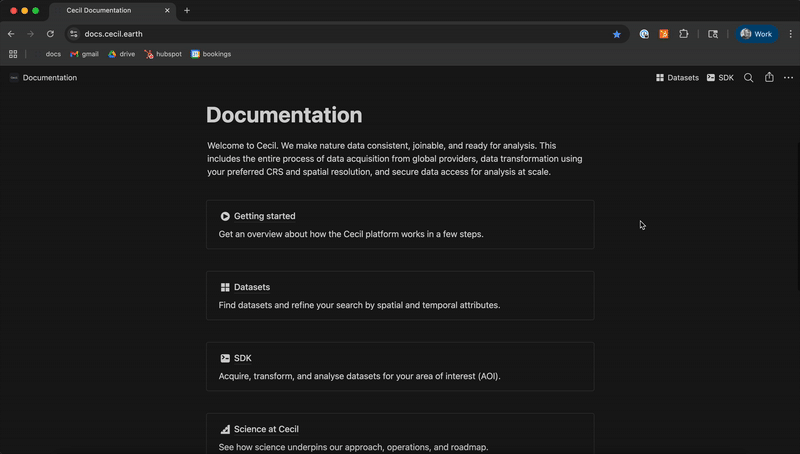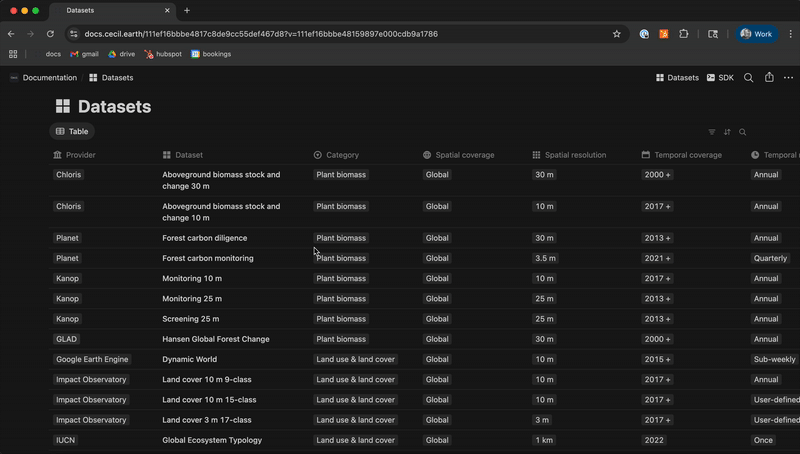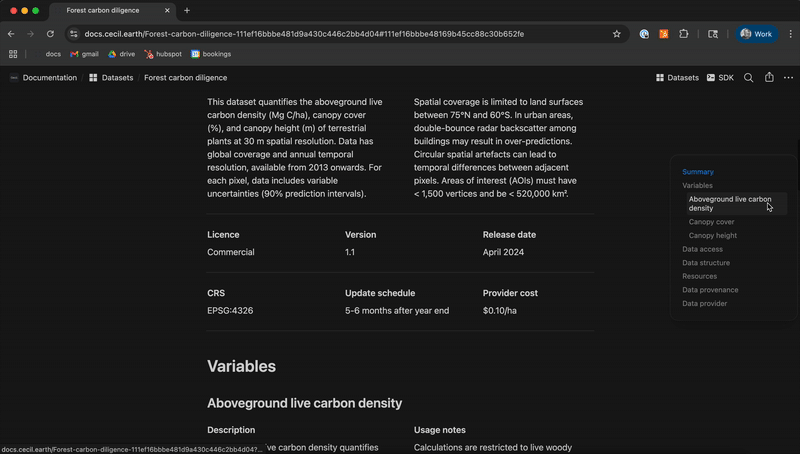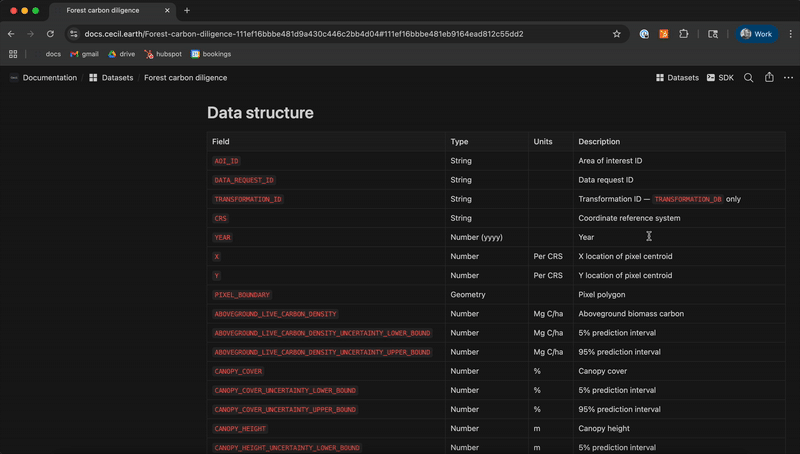
At Cecil, we enable dataset inspection by providing standardised dataset documentation for all datasets, as well as making it straightforward to sign up, request data for an area of interest, and begin working with the data. See our documentation to get started.
Cross-comparisons
Cross-comparisons go beyond dataset inspection to examine how datasets perform relative to each other. Cross-comparisons help to reveal how different sources of uncertainty together affect dataset performance. For instance:
Spatial and temporal comparisons – using pixel-level correlations, difference maps, and time series plots to identify where and when datasets agree or disagree.
Multidimensional comparisons – applying approaches like multidimensional scaling to examine whether datasets with multiple variables and time points show similar patterns overall.
Uncertainty analysis – exploring uncertainty values to identify where confidence intervals overlap (e.g., to flag where high uncertainty may be responsible for disagreement between datasets).
Relative use case sensitivity – comparing the ability of different datasets to detect a relevant event (e.g., deforestation in your region of interest).
Ensemble approaches – treating multiple datasets as an ensemble (e.g., using the median as an estimate and spread between datasets as an indicator of uncertainty).
To do cross-comparisons, you must first align datasets. Cecil handles this by delivering all data into one database and allowing users to join datasets at the pixel level by transforming them to the same coordinate reference system and spatial resolution.
Try this Jupyter Notebook to get started with basic cross-comparisons of plant biomass datasets on Cecil.
Benchmarking
The gold standard of dataset evaluation is to benchmark accuracy against an accepted source of truth (e.g., validating weather models against meteorological station observations).
For nature data, this creates a challenge: the source of truth is usually field data that contains its own uncertainties. Field surveys to assess bird diversity can miss species that rarely sing, and converting tree basal area measurements into biomass estimates carries inherent uncertainty. Even so, high quality field data remains the best available reference point for evaluating dataset performance.
A typical benchmarking analysis evaluates how dataset values deviate from those of a field reference dataset while accounting for uncertainty in both datasets. The more comprehensive the field reference dataset the better – benchmarking should ideally consider all regions, ecosystems, and contexts (e.g., coastlines, steep slopes) covered by the test dataset. This poses another challenge: generating a comprehensive reference dataset of sufficient scale for global usage is an expensive and monumental task.
We are working with the community to resolve this, and expect to bring reference datasets onto the Cecil platform soon. Join our Slack community if you’d like to stay updated and join the conversation with over 250 nature data enthusiasts.
Towards standardised dataset evaluation
The nature data sector has yet to implement dataset evaluation as standard practice. Data providers inconsistently publish performance metrics, and licensing restrictions can hinder third-party assessments. At the same time, the challenges of benchmarking against imperfect field data make it easy to avoid dataset evaluation entirely.
Thankfully, this is changing. Organisations like Sylvera and Adventure Scientists are building rigorous field reference datasets. Companies like Equitable Earth (formerly ERS) have begun to publish their benchmarking reports. At Cecil, we are making dataset evaluation accessible by building tools to inspect, compare, and benchmark datasets in nature data workflows.
Dataset evaluation will ultimately reveal limitations and uncertainties, but this transparency will yield more reliable and actionable insights. Better decisions come from understanding what our data can and cannot tell us.
If every map is imperfect, we should strive to know where the imperfections lie.
Recent updates at Cecil:
Planet’s two soil moisture content datasets are now available on Cecil
WRI’s SBTN Natural Lands dataset is now available on Cecil
Join our Slack Community to join the conversation with over 250 nature data enthusiasts
Sign up for a Cecil account and get started here.
I want to acknowledge that an image previously included in this newsletter was missing information and context. As a result, it may have led to confusion or incorrect assumptions about the analysis in the image.
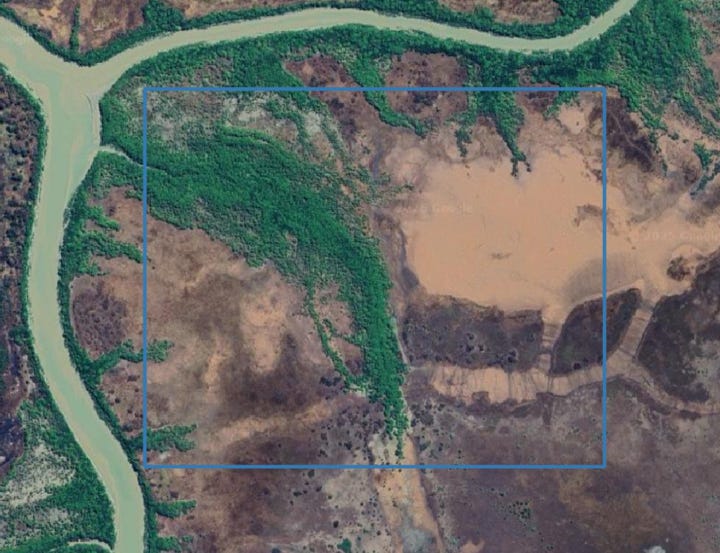
The image represented pairwise scatter plots of aboveground biomass (AGB; Mg/ha) values from Chloris Geospatial, Kanop, and Planet datasets (dotted line = 1:1). Points are all annual pixel values spanning 2013-2024 from one AOI (118 ha) in Kakadu National Park, Australia (N = 316536). Datasets were transformed to the same coordinate reference system (EPSG:4326), spatial resolution (0.00025º; ~ 30 m on the equator), and pixel grid.
To provide more context, I’ve included an aerial image of the AOI.
At Cecil, we’re fortunate to work with world-class data providers who are actively shaping the future of environmental markets. We’re grateful not just for our partnerships, but for their transparency and commitment to building a robust ecosystem.
Our partners are already deeply engaged in efforts aligned with the framework we outlined, including:
Publishing detailed dataset pages on our platform, with usage notes, accuracy assessments, technical specs, and fact sheets
Participating in initiatives like the Equitable Earth AGB benchmark: https://docs.ers.org/standard1.0/agb-benchmark.pdf
There’s still a long road ahead and collaboration will be key to getting it right. Thank you for all your comments and discussions from this newsletter.