
Selecting nature data sources
Using domain specific criteria to select plant biomass data sources.

Welcome to the Nature Data Newsletter. Each month, we share insights with data enthusiasts, GIS experts, and investors learning about nature data.
Selecting nature data is difficult.
Teams face obstacles when shortlisting and evaluating new data sources:
No one dataset can serve all purposes - different sources vary across spatial and temporal factors.
Nature data is specific to local context - the same source may yield different insight in different places.
We spoke to 30+ subject matter experts, nature practitioners, and financial institutions to learn how they are tackling these challenges today.
We heard stories about spreadsheet workarounds listing known datasets and painful searches for supporting documentation.
Dataset documentation is often locked away in the bowels of repository websites. You have to click 15 links to get to the appendix that you want. (Will Mulhern, Y Analytics)
In addition to identifying issues, we discovered that teams are using consistent and repeatable criteria to select plant biomass data sources for analysis.
In this newsletter, we summarise our findings to help you succeed in your next plant biomass data selection process.
View our plant biomass data source criteria here.
Using reproducible criteria to select plant biomass data sources
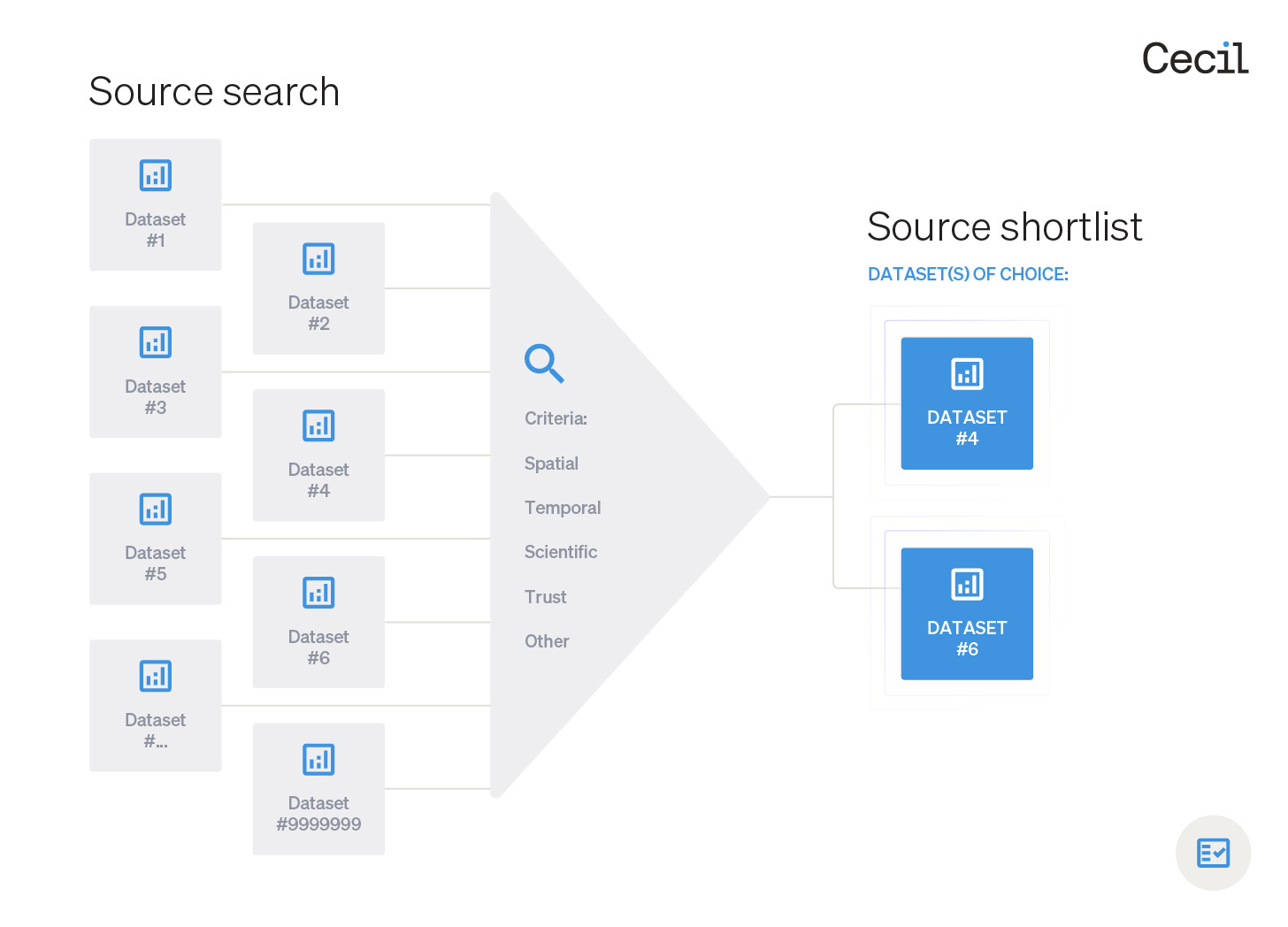
After identifying your required plant biomass variable and gathering potential data sources from open repositories (e.g., Google Earth Engine) or commercial data providers (e.g., Planet), the following criteria can be used to shortlist datasets for analysis:
1. Spatial
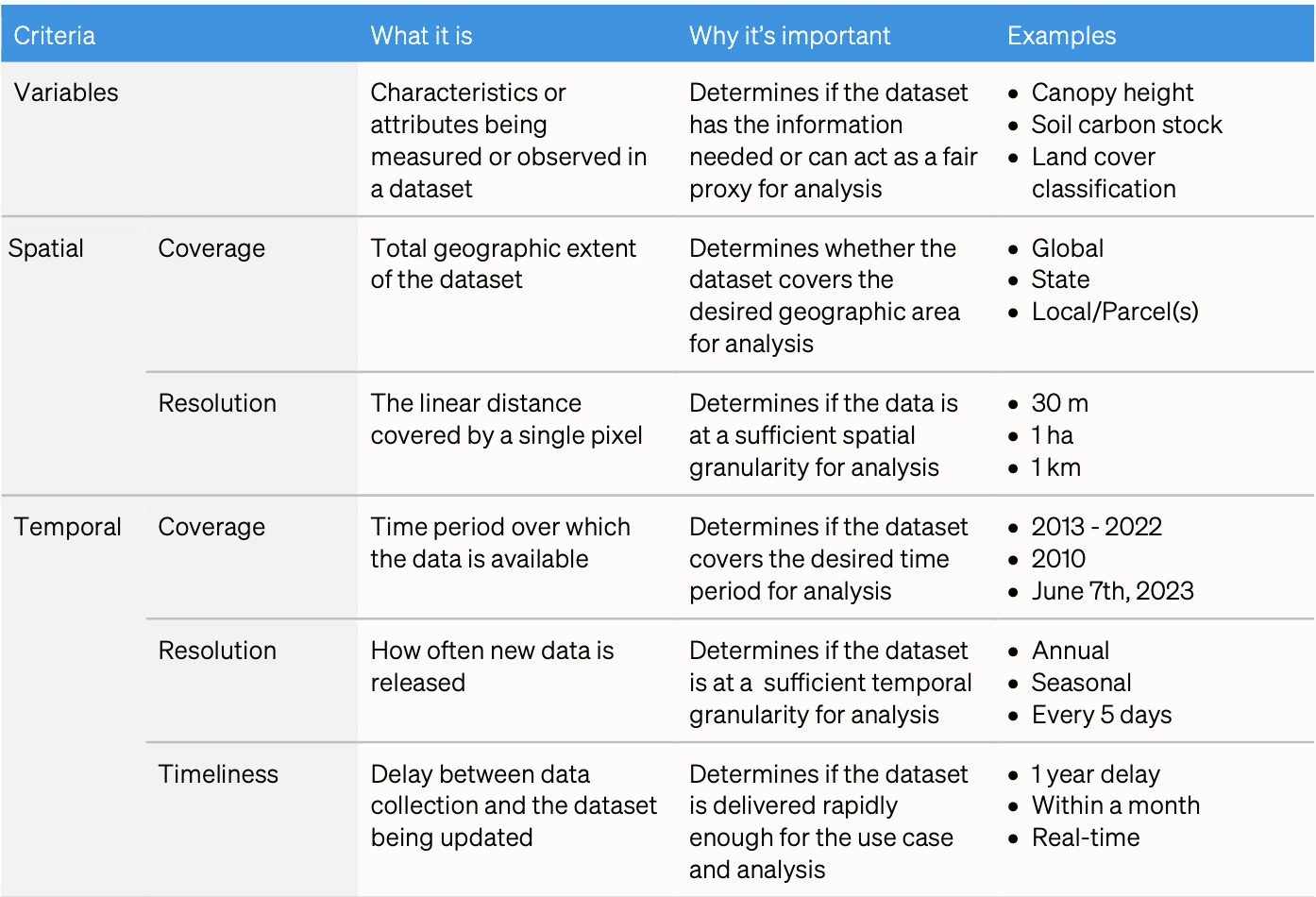
Spatial coverage: The total geographic extent of the dataset. This determines whether the dataset covers the desired geographic area for analysis. Example: global.
Spatial resolution: The linear distance covered by a single pixel. This determines if the data is at a sufficient spatial granularity for analysis. Example: 30 m.
2. Temporal
Temporal coverage: The total time-period over which the data is available. This determines if the dataset covers the desired time-period for analysis. Example: 2013-2022.
Temporal resolution: How often new data is released. This determines if the dataset is at a sufficient temporal granularity for analysis. Example: Every 5 days.
Timeliness: The delay between data collection and the dataset being updated. This determines whether data can be accessed fast enough to make decisions about a use case. Example: Within one month.
3. Scientific
Accuracy: The numerical proximity of the measurements to the true value. This determines how close to the truth a dataset is. Example: Within 10% of accepted reference standard, such as permanent field plots.
Precision: The numerical similarity of multiple repeat measurements. This determines how repeatable the values in the dataset are. Example: Replicate measurements within 10% of each other.
Uncertainty: The numeric confidence interval within which the true value sits. This determines the degree of confidence associated with a dataset. Example: 80 m ± 15 m (mean ± 95% confidence intervals).
4. Trust
Transparency: The accessibility, completeness, and readability of the methods, metadata, validation process, and other information. Can you trust the data yourself? Example: Technical documentation.
Informal endorsements: Peer, personal network, and professional community feedback on the dataset. Provides community validation of trustworthiness. Example: Trusted academic colleague uses regularly.
Formal endorsements: Independent third party publications on the dataset. Provides formal institutional validation of trustworthiness. Example: Scientific papers.
5. Other factors
Cost: The cost of accessing the data. This determines if the dataset is affordable. Example: $0.25 per ha per year.
Completeness: The proportion of complete records in the dataset. This impacts the proportion of data that can inform the specific use case. Example: Random data corruption from sensor or transmission error.
Local relevance: The location(s) of ground truth or other calibration data used to train or validate datasets. This indicates where data are likely to perform better or worse. Example: cloud forest, Ecuador.
Restrictions: Are there limitations on the use or sharing of the data? This influences whether the dataset is usable for the specific use case. Example: Non-commercial use only.
Data format: Structure and content of the data output. This determines compatibility with platforms, workflows, tools, and integrations. Example: GeoTIFF.
Storage and compute: The load on storage and/or compute systems. This determines usability around additional costs, resources, and project timelines. Example: File size.
The criteria factsheet
We created a criteria factsheet to support your next plant biomass data search.
Please send feedback to hello@cecil.earth so we can improve this resource for the nature data community.
In next month's newsletter, we'll share Cecil’s catalogue of quality plant biomass data sources.

Insights
1. No data is clean
“No data is clean, but most is useful.” Dean Abbott, Chief Data Scientist - SmarterHQ
2. Agreeing on nature data
“In order to build a greener economy we need to reconfigure the connections between Nature, Policy, and Capital. And the first step in the right direction is agreement on data.” Marcelo Bicalho Behar, Vice-President - Natura &Co
3. The demand for transparency
“Greater transparency of data product process and methodology should be addressed in tandem. Regardless of the type of data that is being used to assess nature-related risks, data use and methodological decisions should be fully transparent (including peer-review) to allow for a traceable and replicable assessment.” - TNFD Data Discussion Paper

Learn
Nature data provider Kanop share their scientific approach to measuring ecosystem services.
Peter Hurley outlines his approach to modelling ecosystem connectivity.
‘Forest 500: A Decade of Deforestation Data’ report uses 1.3 million data points to set out 10 lessons for accelerating action on tropical deforestation.
Interested in biodiversity finance? The Bloomlabs newsletter by Simas Gradeckas is a great place to start.
Notice Board
Cecil is seeking nature data enthusiasts to give feedback on their data infrastructure. More details here.
terraPulse announce partnership with Island Conservation to monitor benefits of invasive mammal eradications on island ecosystems.
Planet adds to its planetary variable product suite with automated field boundary detection.
Cecil is seeking partners to develop resources that simplify the sharing of first party nature data. More details here.
Broadbent et al. find that future climate change could diminish the capacity of alpine ecosystems to retain nutrients.
The GBIF Secretariat is calling for proposals to analyse trends in use of GBIF-mediated data in peer-reviewed literature.
Thank you
Thanks for reading and for supporting Cecil. A special thank you to everyone who supported us this month with feedback, introductions, and advice:
Arthur Broadbent, Johnny Wilson, Romain Fau, Franzi Schrodt, Jamie Batho, Simas Gradeckas, Will Mulhern, Sean Chua, Matt Taylor and Elaine Mitchell.

Enjoy the newsletter? Please forward to a friend.
Do you have a nature data announcement to share with this community? Please contact hello@cecil.earth and we’ll include it in the next issue.
This newsletter is curated by Cecil. From curating data providers, to preparing data for analysis, Cecil’s nature data infrastructure helps data teams access accurate and precise nature data. They are trusted by teams such as Foresight Sustainable Forestry, Kilter Rural, and Impact Ag Partners to manage data on 3,000+ natural assets and 3+ million hectares.